理化学研究所(理研)生命機能科学研究センター バイオコンピューティング研究チームのソ・セキイ 特別研究員、田中 信行 上級技師らの研究チームは、ポリマー[1]の表面にどれくらいのタンパク質が吸着するかを、最新の人工知能(AI)技術を用いて高精度予測するAIモデル[2]「BB-EIT(Bio-interface BERT Encoder for Interaction Translation)」を開発しました。
本技術は、生体と接しても汚れが付きにくい表面材料や培養皿上での細胞接着の制御、高性能センサーといった次世代バイオ材料[3]の設計を大幅に効率化すると期待されます。
バイオ材料の開発において、表面を覆うポリマー素材へのタンパク質の吸着を精密に制御することは重要です。しかし、ポリマーとタンパク質の複雑な相互作用をAIで予測するためには、良質なデータの不足が大きな課題となっています。
AIモデル「BB-EIT」は、ポリマーの厚さや表面の電気的性質などの物理的・生化学的な特徴量を組み合わせて学習を行います。BB-EITの基盤モデル[2]には、自然言語処理技術[4]により化学構造式の情報を「言葉」のように読み解く大規模言語モデル[5]「ChemBERTa[6]」を採用しました。さらに、構造式の表記を数学的に組み替えるデータ拡張法でデータを増やすことで、少ない実験データからでも高い予測精度を実現しました。BB-EITは、ポリマーとタンパク質の相互作用を支配する物理原則を捉えて予測を行っており、広範な材料とタンパク質の組み合わせに対して吸着傾向を正しく導き出せる汎用性(はんようせい)があります。
本研究は、科学雑誌『ACS Applied Materials & Interfaces』オンライン版(4月6日付:日本時間4月6日)に掲載されました。
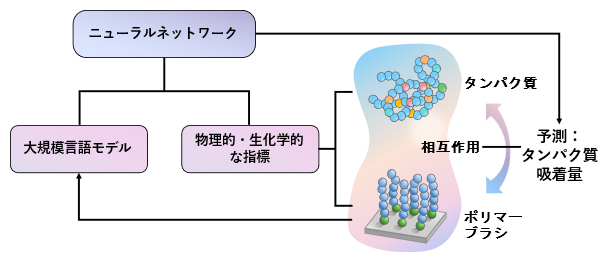
化学構造式を読み解く大規模言語モデルと物理的・生化学的な特徴量を組み合わせたBB-EIT
背景
生体に直接接触する人工臓器などの医療機器において、材料表面とタンパク質をはじめとする生体成分との相互作用を制御することは極めて重要です。この材料表面と生体成分の境の面である「バイオ界面」におけるタンパク質吸着量の定量的制御は、コンタクトレンズや人工血管における防汚性材料設計の最重要課題の一つです(図1左)。一方で、タンパク質の材料表面への吸着・結合現象は、細胞・オルガノイド(ミニ臓器)培養におけるタンパク質の保持、疾患の早期診断を可能にする高感度なバイオセンサー、患部へ的確に薬剤を到達させるドラッグデリバリーシステム(DDS)[7]の基盤技術としても応用されます(図1右)。このように、界面におけるタンパク質吸着の精密な制御は、抵抗(rejection)と固定化(immobilization)という相反するニーズに応えるものであり、その応用範囲は医療・バイオテクノロジーの広範な領域にわたります。
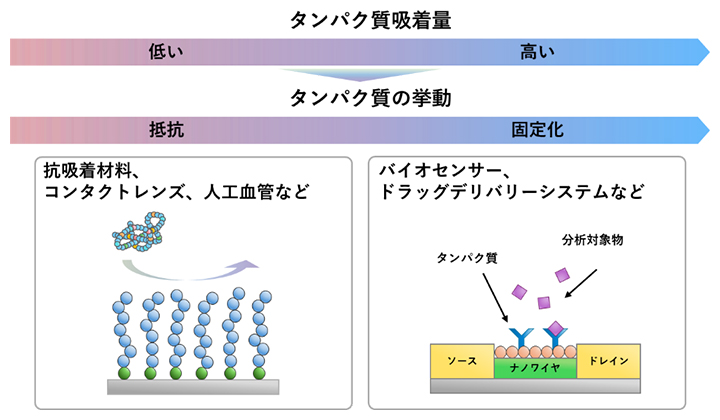
図1 バイオ界面におけるタンパク質吸着・結合現象とその応用例
目的に応じたタンパク質吸着量制御の例。コンタクトレンズや人工血管などの表面を抗吸着材料でコーティングすると、汚れや詰まりを低減させることができる。一方、バイオセンサーやドラッグデリバリーシステムなどでは、タンパク質を吸着させて検査感度や薬効を高めることができる。
これまで、この分野の研究は、研究者の経験に基づく膨大な「試行錯誤」の繰り返しによって進められてきました。しかし、材料とタンパク質という二つの複雑な物質が絡み合う現象を正確に捉えるのは至難の業です。吸着量は、材料の化学的な性質だけでなく、物理的あるいは生化学的な特性、さらにはタンパク質自体の性質など、多くの要因が複雑に絡み合って決まるからです。近年はAIを用いた材料開発も進められていますが、実験データを得るには多大な時間とコストがかかるため、機械学習[8]を用いた予測モデルも、特定のタンパク質や材料にしか通用しない「限定的なモデル」にとどまっていました。多様な材料とタンパク質の組み合わせを一つの枠組みで横断的に予測できる「汎用性」の欠如が、データ駆動による材料設計を阻む大きな障壁となっていたのです。
このような背景の中、本研究は、「大規模言語モデル」と、材料科学の専門知見を融合させることで、データ不足の壁を突破しようと試みました。化学構造という「言葉」を深く読み解く力と、物理的な特徴をデジタル情報として統合し、さらに少ないデータから豊かな情報を引き出す革新的な手法を採用することで、これまで困難とされてきた「多様なシステムを網羅する汎用的な吸着予測モデル」の構築という高いハードルに挑みました。
研究手法と成果
バイオ材料には、生体に対して毒性が少なく、加工・大量生産が容易な高分子(ポリマー)が多く用いられています。ポリマーは、特定の化学構造を持つモノマー[1]が鎖のように多数つながったもので、どのモノマーを選択するかによって化学的性質や物理的性質を制御することができます。このポリマーの応用形態の一つとして、固体表面に固定された多数のポリマーが上に伸びてブラシ状となった「ポリマーブラシ[9]」があります。ポリマーブラシはさまざまな材料に新たな表面機能を付加する技術として、研究が進められています。
本研究で開発した予測モデル「BB-EIT(Bio-interface BERT Encoder for Interaction Translation)」は、特定のモノマーから成るポリマーブラシの表面にどれくらいのタンパク質が吸着するかを高精度予測できるAIモデルです。このモデルの基盤には、膨大な化学構造データを事前に学習し、その化学構造式を「文脈」として理解することができる大規模言語モデル「ChemBERTa」を採用しました。BB-EITの構築における最大の特徴は、ChemBERTaの強力な言語モデルの機能を維持したまま、ポリマーブラシの物理的な特性やタンパク質固有の性質を後付けの層として結合させた点にあります。
具体的な予測プロセスでは、まず高分子の最小単位であるモノマーの構造を「SMILES文字列[10]」としてChemBERTaに入力し、そこから768次元[11]の化学的特徴ベクトル[11]を抽出します。ここに、重要な物理・生化学的パラメーター、すなわちポリマーブラシ材料の「膜の厚さ」「表面親水性・疎水性[12]」「表面電位[13]」と、タンパク質の「表面電位」「分子量」を5次元のベクトルとして直接結合させます。これにより、AIは化学構造というミクロな情報と、材料表面の状態やタンパク質の性質といったマクロな情報の両方を加味して、最終的なタンパク質吸着量を算出することが可能になります(図2)。
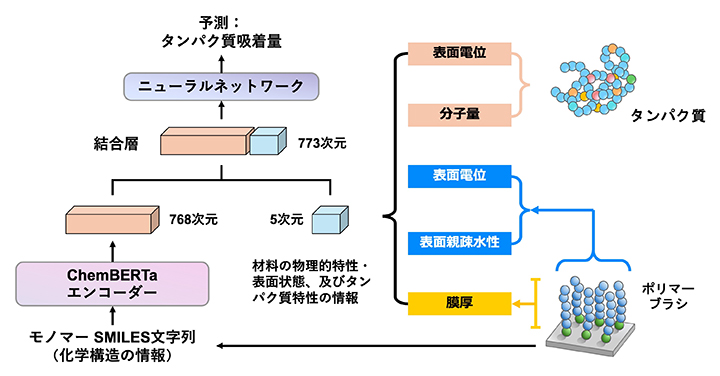
図2 AIモデルBB-EITの構造
ChemBERTaは、SMILES文字列に変換したモノマーの化学構造式を「文脈」として理解し、コンピュータで処理する形式(768次元の化学的特徴ベクトル)として出力(エンコード)する。この化学的特徴ベクトルに、「膜(ポリマーブラシ)の厚さ」「表面親水性・疎水性」「表面電位」と、タンパク質の「表面電位」「分子量」という物理・生化学的特徴を示す5次元のベクトルを結合させる。こうして、一つのモノマーに対して得た合計773次元の特徴ベクトルを機械学習(ニューラルネットワーク)にかけ、予測値(タンパク質吸着量)を出力する。
モデルの学習に当たっては、ソ特別研究員らが先行研究で収集した高品質な実験データが活用されました注1)。ここにはウシ血清アルブミン(BSA)、リゾチーム(Lys)、フィブリノーゲン(Fib)の3種類のタンパク質が、親水性や電荷の異なるさまざまな高分子材料に吸着した際のデータ(101件)が含まれています。しかし、ChemBERTaを十分に訓練するにはこれらのデータ数は極めて少なかったため、本研究は「データ拡張法」という手法を導入しました。これは、一つの化学構造に対して複数の書き方が存在するSMILES文字列の性質を利用し、表記のバリエーションを増やすことで、実質的なデータ数を数十倍の6,400件まで増幅させるというものです。
さらに、現実の実験につきまとう測定誤差を再現するため、拡張されたデータにはガウスノイズ[14]が加えられました。この処理により、AIは特定の数値に過学習[8]することなく、物理現象の本質的なルールを柔軟に学習できるようになりました。
開発されたBB-EITモデルの予測精度を表す評価指標は、テストデータに対して0.88という極めて高い予測精度を記録しました(1に近いほど予測精度が高い)。これは、拡張しなかった元のデータのみで学習させた場合の精度(0.73)を上回る結果です(図3a)。
研究チームは、AIが何を重視して予測を行ったかを解明するために「SHAP分析[15]」を実施しました。その結果、タンパク質とポリマーブラシの表面電位といった電気的な相互作用に関わる特徴量が大きな影響を与えていることが定量的にはっきりと示されました。また、表面親水性・疎水性も予測に寄与しており、BB-EITが「化学構造」「静電気」「疎水性」というポリマーとタンパク質の相互作用を支配する物理原則を正しく捉えていることが証明されました。
モデルの汎用性を試すために行われた「外部検証」では、学習データには一切含まれていない材料やタンパク質を用いた予測が試みられました。具体的には、PSBMAという未学習のポリマーに対する、リゾチームや未学習のタンパク質(ホスホグリセリン酸キナーゼ)の吸着量を予測させたところ、実際の測定値に近い数値を予測し、両者の相互作用の特性を正しく導き出していることが確認できました(図3b)。
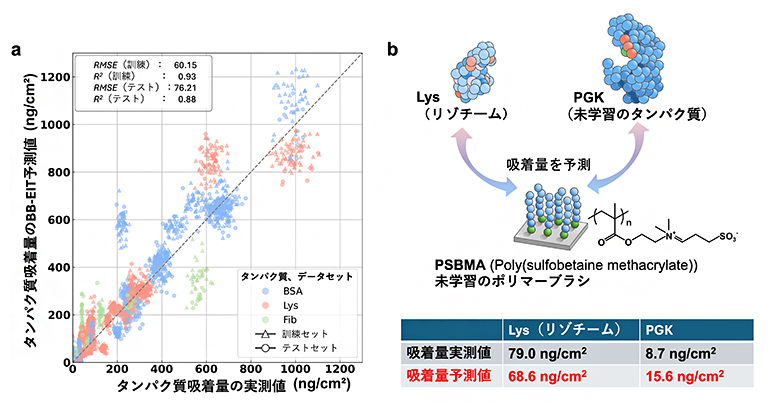
図3 モデル予測精度と汎用性
- (a)ポリマーブラシ表面におけるタンパク質吸着量の実測値(横軸)と、BB-EITによる予測値(縦軸)の相関を示している。テストセット(学習に用いなかったデータセット)に対する評価指標(決定係数R2:1に近いほど予測精度が高い)は0.88となり、AIを用いた予測モデルとして極めて高い精度を達成した。グラフ内のプロットは、タンパク質の種類(青:ウシ血清アルブミン(BSA)、赤:リゾチーム(Lys)、緑:フィブリノーゲン(Fib))およびデータセット(三角:訓練セット、円:テストセット)を表している。RMSE:二乗平均平方根誤差
- (b)今回の学習に用いなかった素材(PSBMA)のポリマーブラシ上への、リゾチーム(Lys)およびPGK(ホスホグリセリン酸キナーゼ:未学習タンパク質)の吸着量をBB-EITで予測し、報告された吸着量(実測値)と比較した。いずれも、実際の測定値と近い数値を予測した。
ng/cm2:1平方cm当たりナノグラム(ng、1ngは10億分の1グラム)。
これらの成果は、BB-EITが特定の実験結果を暗記するのではなく、広範なバイオ界面現象を横断的に理解できる「基盤モデル」としてのポテンシャルを有していることを強く物語っています。
- 注1)Su, S.; Masuda, T.; Takai, M. Machine Learning for Quantitative Prediction of Protein Adsorption on Well-Defined Polymer Brush Surfaces with Diverse Chemical Properties. Langmuir 2025, 41 (11), 7534-7545.
今後の期待
本研究が提案するBB-EITの最大の新しさは、これまで個別に研究されていた多様なタンパク質と高分子の複雑な関係を、統一されたAIモデルによって、かつ未知の材料に対しても予測可能にした点にあります。これにより、これまでの材料開発を支えてきた膨大な時間と費用を要する「試行錯誤」から解放され、コンピュータ上で最適な材料をあらかじめ選定する「データ駆動型」の設計へと世界が大きく変わります。
現在は強力な基盤となる予測モデルが確立された段階であり、今後はタンパク質の詳細な情報や、体内の複雑な身体環境変化を反映させる改良を進めていきます。これにより、数年以内には特定の病気に最適化したドラッグデリバリーシステムや高度な診断デバイスなどの応用研究において、実用レベルでの設計支援が実現することを目指しています。この歩みは、バイオテクノロジーにおける材料設計をより精密かつ迅速なものへと進化させ、私たちの生活を支える医療技術の向上に直結する重要な一歩となります。
補足説明
- 1.ポリマー、モノマー
モノマーは「小さな分子の粒」で、それがたくさん鎖のようにつながってできた大きな物質がポリマー(高分子)となる。ネックレスを例にすると、一粒の真珠がモノマー、つながったネックレス全体がポリマーに相当する。 - 2.AIモデル、基盤モデル
AIモデルは、コンピュータにデータを学習させ、特定の判断や予測ができるようになった「知能の仕組み」のこと。人間でいうところの「学習済みの脳」のような役割を果たす。基盤モデルは、幅広い知識をあらかじめ学習しており、少しの調整で翻訳、画像作成、分析などさまざまな用途に応用できる「土台」となるAIモデル。 - 3.バイオ材料
ここでは、医療や生物学の分野で使われる、体になじみやすい材料の総称。人工血管やコンタクトレンズのように、生体組織と直接触れ合っても拒否反応が起きにくい素材を指す。 - 4.自然言語処理技術
人間が日常的に使う言葉(自然言語)を、コンピュータに理解させたり処理させたりする技術。翻訳アプリやスマートスピーカーの対話機能など、言葉を扱うAIの根幹を支えている。 - 5.大規模言語モデル
膨大なデータセットを用いて情報のパターンや文脈を学習した高度なAIの総称であり、自然言語の処理だけでなく、化学構造など逐次的に処理していくようなデータの解析にも応用される。ChatGPT、Geminiなどがその代表例。 - 6.ChemBERTa
SMILES文字列([10]参照)で表現した化学構造データを大量に学習させた大規模言語モデルであり、分子の構造からその物理的・化学的な性質を予測することに特化したAI。プレプリント注2)で報告された。- 注2)Chithrananda, S.; Grand, G.; Ramsundar, B. ChemBERTa: Large-Scale Self-Supervised Pretraining for Molecular Property Prediction. arXiv October 23, 2020. http://arxiv.org/abs/2010.09885 (accessed 2023-08-01)
- 7.ドラッグデリバリーシステム(DDS)
薬を体内の「必要な場所」へ、「必要な時」に、「最適な量」で届けるための工夫や技術のこと。副作用を抑えつつ、薬の効果を最大限に高める「狙い撃ち」の技術といえる。DDSはDrug Delivery Systemの略。 - 8.機械学習、過学習
機械学習は、コンピュータが大量のデータからパターンやルールを自ら見つけ出し、学習する技術。人間が細かく指示しなくても、経験を積むほど予測や判断の精度が上がっていく特徴がある。ただし、学習に用いたデータに過剰に適合した結果、未知のデータに対する予測精度が低下する現象も知られており、これを過学習と呼ぶ。 - 9.ポリマーブラシ
基板の上にポリマー形成の起点となる重合開始層をつくり、そこからポリマーを成長させることで、ポリマーがブラシのように密に生えそろった表面構造。表面の特性を精密にコントロールできるため、先端材料の研究で多用される。 - 10.SMILES文字列
分子の化学構造をアルファベットや記号を用いて1行の文字列で表現した記述方法。図を描かなくても、テキスト情報だけでAIに化学構造を正確に伝えることができる。 - 11.次元、ベクトル
ベクトルは、データのさまざまな特徴を「数値の並び」として表現したもの。AIは言葉や画像をこの数値の塊に置き換えることで、情報の「近さ」や「違い」を計算できるようになる。データの持つ「情報の項目(ベクトル)の数」を次元と呼ぶ。 - 12.表面親水性・疎水性
材料の表面がどれくらい水になじみやすいか(親水性)、あるいは水を弾きやすいか(疎水性)を示す性質。下記の先行研究注3)より、ポリマーブラシの表面が水になじみやすいほど、タンパク質の吸着を抑制する効果が高まる傾向があることが分かっている。- 注3)Nagasawa, D.; Azuma, T.; Noguchi, H.; Uosaki, K.; Takai, M. Role of Interfacial Water in Protein Adsorption onto Polymer Brushes as Studied by SFG Spectroscopy and QCM. J. Phys. Chem. C 2015, 119, 17193-17201, DOI: 10.1021/acs.jpcc.5b04186
- 13.表面電位
材料の表面が電気的にどのような状態にあるかを示す指標。タンパク質も種類によって異なる電気的な性質を持っているため、材料表面の電位と引き合ったり反発したりすることで、吸着する量が大きく変化する。 - 14.ガウスノイズ
自然界でよく見られる、平均値の周りにバランスよく散らばる「ランダムな雑音」。 - 15.SHAP分析
AIがなぜその答えを出したのか、どの情報が判断にどれくらい影響を与えたのかを数値で見える化する手法。「ブラックボックス」になりがちなAIの判断理由を説明するために役立つ。
研究チーム
理化学研究所
生命機能科学研究センター バイオコンピューティング研究チーム
特別研究員 ソ・セキイ(SU Shiwei)
上級技師 田中 信行(タナカ・ノブユキ)
チームディレクター 高橋 恒一(タカハシ・コウイチ)
(最先端研究プラットフォーム連携(TRIP)事業本部 科学研究基盤モデル開発プログラム プロジェクトディレクター)
最先端研究プラットフォーム連携(TRIP)事業本部
科学研究用共通基盤モデル開発チーム
チームディレクター 牛久 祥孝(ウシク・ヨシタカ)
研究支援
本研究は、理研TRIPイニシアティブ(AGIS)により実施しました。*AGIS:Advanced General Intelligence for Science Program(科学研究基盤モデル開発プログラム)
原論文情報
- Shiwei SU, Nobuyuki TANAKA, Yoshitaka USHIKU, Koichi TAKAHASHI, "BB-EIT: A Generalized Prediction Model for Protein Adsorption on Polymer Brushes Using Augmented Chemical Embeddings", ACS Applied Materials & Interfaces, 10.1021/acsami.5c25223
発表者
理化学研究所
生命機能科学研究センター バイオコンピューティング研究チーム
特別研究員 ソ・セキイ(SU Shiwei)
上級技師 田中 信行(タナカ・ノブユキ)
 ソ・セキイ
ソ・セキイ
発表者のコメント
最新のAIが単なる文章作成ツールにとどまらず、医療の安全性を高める防汚材料や、わずかな病気の兆候を捉えるバイオセンサーの開発を支える「頼もしい科学のパートナー」として社会に浸透し始めていることをお伝えしたいと考えています。最新のAIと材料科学の知見を融合させることで、世界で初めて一つの枠組みで材料に対するタンパク質吸着量を正確に予測することに成功し、さらに未知の材料にも対応できる高い汎用性を実現しています。このモデルが、次世代のバイオ材料開発を劇的に加速させる強力な基盤の一つになるよう利用促進を図りつつ、さらなる性能向上版BB-EITの開発に取り組んで参ります。(ソ・セキイ)
報道担当
理化学研究所 広報部 報道担当
お問い合わせフォーム